
2. 标记结构
本章节将介绍基本的内存标记结构,包括chunk, tree chunk, sbin, tbin, segment, mstate等.这些重要的机构组成了dlmalloc分配算法的基础.
2.1 chunk
chunk是dlmalloc中最基本的一种结构,它代表了一块经过划分后被管理的内存单元. dlmalloc所有对内存的操作几乎都聚焦在chunk上.需要注意的是, chunk虽然看似基础,但不代表它能管理的内存小.事实上chunk被划分为两种类型,小于256字节的称为small chunk,而大于等于256字节的被称为tree chunk.
2.1.1 chunk布局
在dlmalloc的源码中有一幅用字符画成的示意图,套用Doug Lea本人的话说 “is misleading but accurate and necessary”.初次接触这种结构划分会觉得既古怪又别扭. 因此,接下来的几节内容需要认真体会,让大脑适应这种错位的思考.
对于一个已分配chunk, 它在内存中可能是这个样子,

上图为了便于理解特意使用了两种颜色来描述,蓝色区域的部分代表当前的已分配chunk,而黄色区域代表上一个和下一个chunk的部分区域.
解释一下其中的含义, 从蓝色区域开始看, 在已分配chunk的开始记录当前chunk的size信息,同时在最后两个bit位分别记录当前chunk和前一个chunk是否被使用,简称为C和P两个bit位.之所以可以做到这一点,是因为在dlmalloc中所有的chunk size至少对齐到大于8并以2为底的指数边界上.这样,至少最后3位都是0,因此这些多余的bit位就可以拿来记录更多的信息. size信息后面是payload部分,显然,当前chunk的使用信息也会记录在下一个chunk开始的P位上.
而对于一个空闲chunk, 其内存布局应该是这样的,
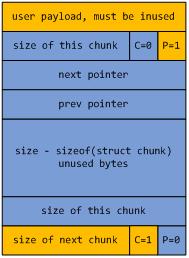
与之前的一致, 蓝色区域代表当前空闲chunk, 黄色区域代表相邻的前后chunk.可以看到空闲chunk与之前的区别在于开始的size后多了next和prev指针,它们把具有相同大小的空闲chunk链接到一起.另一个区别是,在空闲chunk最后同样记录该chunk的大小信息.那么为什么同样的信息要记录两次呢?在下一个小节中会解释这个问题.
另外, 还有一点需要说明的是,空闲chunk的相邻chunk必然是已分配的chunk.因为如果存在相邻两个chunk都是空闲的,那么dlmalloc会把它们合并为一个更大的chunk.
2.1.2 边界标记法(Boundary Tag)
上一节中介绍的chunk布局其实只是理论上的东西,而实现它使用了被称为边界标记法 (boundary tag)的技术.据作者说,此方法最早是大神Knuth提出的.实现边界标记法使用了名为malloc_chunk的结构体,它的定义如下,
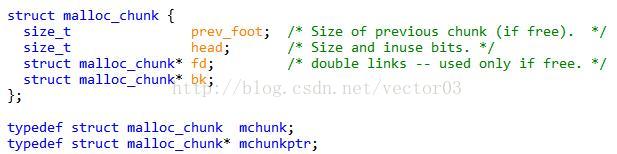
该结构体(以后简称mchunk)由四个field组成.最开始是prev_foot,记录了上一个邻接chunk的最后4个字节.接下来是head,记录当前chunk的size以及C和P位.最后两个是fd, bk指针,只对空闲chunk起作用,用于链接相同大小的空闲chunk.
为了避免读者感到困惑, 在上一节的图中并没有画出对应的mchunk, 现在补充完整如下,
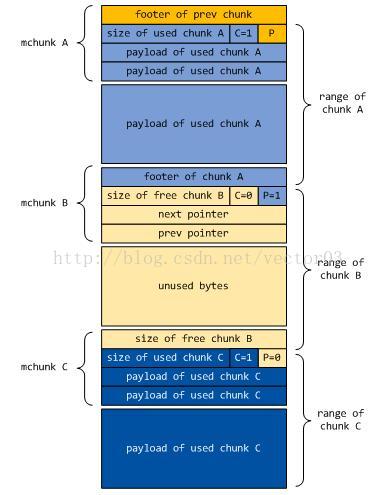
上图用不同颜色画了几个连续交错的chunk,并故意在中间断开,标注出mchunk以及chunk的实际范围,由此得到如下的结论,
1. mchunk的作用是将连续内存划分为一段段小的区块, 并在内部保留这些区块的信息.
2. mchunk最后的fd, bk是可以复用的,对于空闲chunk它们代表链接指针,而已使用chunk中这两个field实际上存放的是payload数据.
3. mchunk与chunk不是一个等同的概念.这一点是容易让人混淆和困惑的. mchunk只是一个边界信息,它实际上横跨了两个相邻chunk.尽管一般认为mchunk可以指代当前的chunk,因为你可以从它推算出想要的地址.但从逻辑上,它既不代表当前chunk也不代表prev chunk.
4. prev_foot字段同样是一个可复用的字段. 一般情况下它有三种含义,如果前一个相邻chunk是空闲状态,它记录该chunk的大小(图中mchunk C).其目的就是你可以很方便的从当前chunk获得上一个相邻chunk的首地址,从而快速对它们进行合并.这也就是上一小节介绍的空闲chunk会在head和footer存在两个chunk size的原因,位于footer的size实际上保存在下一个mchunk中.如果前一个相邻chunk处于in used状态,那么该字段可能有两种情况.一种情况是FOOTERS宏为1,这时它保存一个交叉检查值,用于在free()的时候进行校验.如果该宏为0,则它没有多余的含义,单纯只是前面chunk的payload数据.
5. 最后还有一点需要注意的是, 尽管前面提到所有chunk size都是对齐到至少等于8的2的指数.但这不意味着mchunk就对齐到这一边界上,因为如前所述mchunk和chunk是两码事.我本人最早在看这部分代码时曾天真的以为mchunk也是对齐的,结果到后面居然完全看不懂,后来才发现这家伙根本没有对齐.
到目前为止, 已经了解了dlmalloc的边界标记法是如何实现的.可能有人会对此感到不以为然,作者为什么要把代码写成这个样子呢?其实,要理解这个意图请换位思考一下,如果实现一个类似的东西,你会怎么写呢?人们很快会发现,不按照这种方式设计,想要达到同样目的几乎是很困难的.因为一个chunk在头和尾存在head和footer(也可能不存在footer),中间是一片长度无法确定的区域.假设按照正常从头到尾的顺序写,这个结构体中间填充多长的内容是没法确定的.因此, Doug Lea巧妙的把除了payload之外的overhead部分合并在一起,作为boundary tag来分割整个内存区域,既能做到很方便的计算,又准确地表达了chunk的结构.
2.1.3 chunk操作
针对mchunk的设计,源码中定义了大量的宏来对其进行操作.由于数量很多加上嵌套,对于阅读源码会造成不小的障碍,因此这里会对一些常用宏进行梳理和简单讲解.

定义size_t的大小和bit位数.注意, dlmalloc中对size_t规定为必须为无符号类型,且与指针类型(void*)等宽度.因此如果目标平台还在使用有符号的size_t,只能使用较旧版本的dlmalloc.

常量定义, 这里使用size_t作为强制类型是为了避免在某些平台上出现错误.
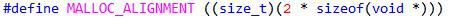
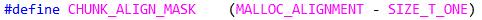
对齐边界和对齐掩码, 边界默认定义为两倍指针宽度, 当然还可以修改的更大,但必须以2为底的指数.有关对齐掩码相关知识请参考1.4.1节.
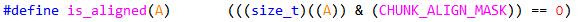
判断给定地址是否对齐在边界上,原理同样在1.4.1节中解释,不再赘述.
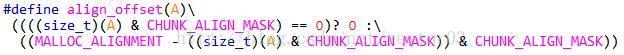
计算给定地址需要对齐的偏移量,请参考1.4.3节中的介绍.

chunk size(实际上是mchunk size,后面不再特意说明)以及overhead大小.注意,如果FOOTERS等于1, overhead将多出4个字节,其实就是在chunk最后放置交叉检查项多出的负载.另外,不管是否有FOOTERS, chunk size本身是不变的.
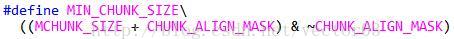
最小chunk大小. dlmalloc中即使调用malloc(0)也是会分配内存的.这种情况下完全不考虑用户payload了,仅仅将chunk size做了对齐.该值的意义在于,这是dlmalloc中除了mmap chunk以外的最坏负载损耗.

这是两个最常用的宏之一, 在chunk和用户地址之前切换.
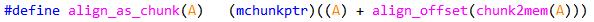
该宏的意思是, 将指定chunk的用户地址对齐,返回对齐后的新chunk地址.理解很容易,从chunk获取用户地址,计算对齐偏移,再移动chunk指针.从这里可以看到, chunk中对齐的并非是mchunk指针,而是用户地址.

将用户请求的内存值转化成实际的内部大小.该宏也是常用宏之一,请求大小先加上overhead(根据FOOTERS而有所不同),再对齐到边界上.
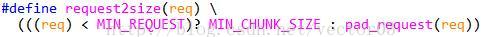
该宏是对上面一系列宏的封装, 如果用户请求小于最小请求, 直接使用最小chunk大小,否则认为正常,转化成内部可用大小.

上面这一组定义了C位和P位,其中FLAG4_BIT并没有实际用途,只是作为未来的扩展.

测试C和P位,分别用掩码做与运算.着重说一下最后两个判断. is_inuse是用C和P的掩码分别测试,然后与P的掩码对比.有人会问这个直接用前面的cinuse不就好了吗?因为存在一种特殊情况,就是被mmap出来的chunk是不见得有邻接chunk的,所以其C和P都被置0. is_inuse就是为了判断包括mmap chunk在内的所有类型chunk的使用情况.理解了这个, is_mmapped就很容易理解了.
计算指定chunk的大小,清除最后3bit后得到的就是size.

对P位的操作.
这是两个计算偏移量的宏, 返回结果被认为是mchunk, 一般用作chunk切割.

这两个也是非常重要的宏. 分别用来计算前一个或后一个邻接chunk的首地址. next_chunk先获取当前chunk的size作为偏移量,再移动chunk指针. prev_chunk则是直接加上前一个chunk的footer作为偏移量.需要注意的是, prev_chunk仅仅适用于前一个邻接chunk为空闲块的情况.如前所述,非空闲chunk这里放置的可能是用户数据或者交叉检查项.实际上这个宏就是用于free时试图与前一个free chunk合并时的判断.
获取下一个chunk的P位,应该与当前chunk的C是一致的.该宏一般用作交叉检查项.
获取和设置当前chunk的footer,因为footer被放在下一个邻接chunk的prev_foot中,因此需要加上size作为偏移量.

该宏是个复合操作, 用于对free chunk进行设置.因为free chunk在head和footer都保存其size,所以首先将其head中写入size.又因为free chunk的P一定是1(否则会与前面合并),因此还需要与P掩码进行一次位与.接着,利用前面的set_foot宏在footer中同样写入size.

这个宏与上面的区别在于多了一个next chunk的P位维护.因为是针对free chunk, next chunk的P需要置0.
2.1.4 tree chunk
之前介绍的chunk其实都属于小型chunk,而较大型的chunk是通过名为malloc_tree_chunk的结构体来描述的.
同mchunk类似tree chunk(以后简称tchunk)开始的field是一模一样的,这就保证了两种类型在基础结构上具有较好的兼容性,降低了代码编写难度. tchunk与前者的区别在于管理上使用不同的结构. mchunk是通过双链表组织起来的,而tchunk使用了一种树形结构,在介绍分箱时会详细说明.因此tchunk中child分别代表了左右子树节点, parent代表父节点, index代表该chunk所在分箱的编号.而fd, bk与mchunk一致,都是用于链接相同size的chunk.另外,需要说明的是,上述结构体字段同样只适用于free chunk,在used chunk上它们都是可复用的
=======================================================================================
我们写过很多C程序了,经常会分配内存。记得刚学C语言时老师说过,可以向两个地方申请内存:一个是栈、一个是堆。小块内存向栈申请,函数调用结束后程序会自动释放内存。大块内存向堆申请,记得一定要自己释放,否则会造成内存泄漏。向堆申请内存直接调用malloc()就可以了,参数是你申请的内存量。释放内存时直接调用free()就可以了,参数是内存块指针。
看似平静的海面,海底则波涛汹涌。当时还没有学操作系统原理,更没有读过Linux内核代码。现在仔细想想才发现申请动态内存是一件多么麻烦的事情。动态内存管理涉及到两个层面的问题:内核层面和用户层面。系统中的内存如何管理这是内核考虑的事情,总不能让应用程序随便使用系统中的内存吧。内核向应用程序提供了接口(为此Linux提供了两个系统调用brk和mmap),当应用程序需要申请内存时向内核提出请求,内核查找并分配一块可用内存供应用程序使用。这部分内容属于内核范畴,不属于C基础库,因此不深入说了。那么用户层面做什么呢?用户层面需要合理管理内存申请和释放请求。比如:brk()可以扩充或收缩堆的大小,你总不能每分配一次内存就调用一次brk()吧?释放内存时更麻烦,你必须保证内存块的释放顺序。比如先申请了内存块a,然后申请了内存块b,然后释放a(b仍然在使用),如果释放a时调用了brk()就会出问题。你不能在使用b的同时释放a。
好在出现了一个叫做“内存分配器”的东西,内存分配器接管了应用程序申请内存和释放内存的请求,应用程序再也不需要直接调用brk()和mmap()了,而是向内存分配器提交申请。有了内存分配器,我们只需要记住malloc()和free()两个接口函数就可以了,其他繁琐事情全部交给内存分配器负责了。申请内存时,内存分配器会一次向内核申请大量内存,然后分批交给应用程序,从而提高了效率。释放内存时,应用程序也是将内存释放给内存分配器,内存分配器在合适的时候再将内存释放会内核。
dlmalloc就是一种内存分配器,由Doug Lea在1987年开发完成,这是Android系统中使用的内存分配器。而Linux系统中采用的是ptmalloc,ptmalloc在dlmalloc的基础上进行了改进,以更好适应多线程。dlmalloc采用两种方式申请内存,如果应用程序单次申请的内存量小于256kb,dlmalloc调用brk()扩展进程堆空间,但是dlmalloc向内核申请的内存量大于应用程序申请的内存量,申请到内存后dlmalloc将内存分成两块,一块返回给应用程序,另一块作为空闲内存先保留起来。下次应用程序申请内存时dlmalloc就不需要向内核申请内存了,从而加快内存分配效率。当应用程序调用free()释放内存时,如果内存块小于256kb,dlmalloc并不马上将内存块释放回内存,而是将内存块标记为空闲状态。这么做的原因有两个:一是内存块不一定能马上释放会内核(比如内存块不是位于堆顶端),二是供应用程序下次申请内存使用(这是主要原因)。当dlmalloc中空闲内存量达到一定值时dlmalloc才将空闲内存释放会内核。如果应用程序申请的内存大于256kb,dlmalloc调用mmap()向内核申请一块内存,返回返还给应用程序使用。如果应用程序释放的内存大于256kb,dlmalloc马上调用munmap()释放内存。dlmalloc不会缓存大于256kb的内存块,因为这样的内存块太大了,最好不要长期占用这么大的内存资源。
dlmalloc中,申请到的内存被分割成若干个内存块,dlmalloc采用两种不同的数据结构表示这些内存块。小内存块保存在链表中,用struct malloc_chunk表示;大内存块保存在树形结构中,用struct malloc_tree_chunk表示。struct malloc_chunk结构如下:
[cpp]
- struct malloc_chunk {
- size_t prev_foot; /* Size of previous chunk (if free). */
- size_t head; /* Size and inuse bits. */
- struct malloc_chunk* fd; /* double links -- used only if free. */
- struct malloc_chunk* bk;
- };
fd表示链表中后面一个malloc_chunk结构,bk表示链表中前一个malloc_chunk结构。head表示这个malloc_chunk代表内存块的大小,另外还包含了一些标志信息。prev_foot表示前一个malloc_chunk的大小,这里的"前一个"不是链表中的"前一个",而是与这个malloc_chunk地址相邻的"前一个"。通过prev_foot和size两个字段dlmalloc就可以快速找到地址相邻的前一个和后一个malloc_chunk结构。
当内存块被分配给应用程序后,就会被从链表中摘除,这时malloc_chunk结构中的fd和bk两个字段就没有意义了,因此可以供应用程序使用。我们调用malloc()申请内存时,malloc()会返回一个指针,指向申请到的内存块的起始地址p,其实这个地址前还有一个malloc_chunk结构,我们可以通过p-8得到malloc_chunk结构的指针。反过来也可以通过malloc_chunk指针得到分配给应用程序的内存块的起始地址。为此dlmalloc定义了两个宏:
[cpp]
- typedef struct malloc_chunk* mchunkptr;
- // 32位Linux系统中,TWO_SIZE_T_SIZES的值是8
- #define chunk2mem(p) ((void*)((char*)(p) + TWO_SIZE_T_SIZES))
- #define mem2chunk(mem) ((mchunkptr)((char*)(mem) - TWO_SIZE_T_SIZES))
我们看下面这个例子:
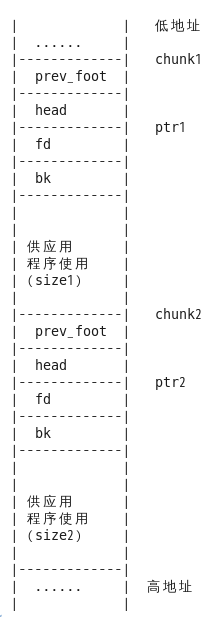
上面这块内存区域中包括两个内存块,分别为chunk1和chunk2,紧接着malloc_chunk结构的就是供应用程序使用的内存。按照前面的分析,fd和bk两个字段也可以供应用程序使用。因此ptr1 = chunk1 + 8,ptr2 = chunk2 + 8。还有一点需要注意的是,只有当前面一个chunk空闲时malloc_chunk结构中的prev_foot才保存前一个chunk的大小;当前面一个chunk分配给应用程序后,prev_foot字段也可以供应用程序使用。上图中,当chunk1分配给应用程序后,chunk2中的prev_foot字段就没有意义了,可以供应用程序使用。dlmalloc返回给应用程序的地址是ptr1,这个内存块的大小是size1 + 8 + 4。因此,malloc_chunk结构中,只有head字段永远不会挪作他用,其他三个字段都可以供应用程序使用,通过这种复用最大限度地减少了dlmalloc本身占用的内存。
dlmalloc对应用程序申请的内存长度有限制,要求内存块长度(包括malloc_chunk结构占用的内存)必须是8字节的倍数。假如应用程序调用malloc(13)申请长度为13字节的内存块,dlmalloc最终分配内存块大小是24字节,除去malloc_chunk结构中head占用的4字节,分配给应用程序的内存块大小是20字节。当然,应用程序不要揣测内存块的实际大小,虽然dlmalloc分配了20字节,但是应用程序最好只使用13字节,不要使用剩余的7字节。否则有两方面后果:(1)应用程序显得混乱,其他人可能无法读懂你的代码。(2)返回多少字节与内存分配器的实现方式有关,换另外一种内存分配器可能返回的就不是20字节了,如果应用程序使用超过13个字节就可能覆盖其他数据了,程序移植性差。
malloc_chunk结构可以表示的最小内存块是16字节,最大内存块是248字节,因此malloc_chunk可以表示16、24、32、40、......、248共30种长度的内存块。dlmalloc定义了30条链表,相同长度的空闲内存块保存在一个链表中。
超过248字节的内存就属于大块内存了,大块内存用malloc_tree_chunk表示,这个数据结构定义如下:
[cpp]
- struct malloc_tree_chunk {
- /* The first four fields must be compatible with malloc_chunk */
- size_t prev_foot;
- size_t head;
- struct malloc_tree_chunk* fd;
- struct malloc_tree_chunk* bk;
- struct malloc_tree_chunk* child[2];
- struct malloc_tree_chunk* parent;
- bindex_t index;
- };
其中prev_foot和head的定义跟malloc_chunk中的定义完全相同。那么其他几个字段表示什么含义呢?dlmalloc中小内存块只有30种情况,可以用30条链表存储;但是大内存块有无数种情况(256、264、272、......),因此就不能用链表表示了,大内存块保存在树形结构中,dlmalloc定义了32棵树存储大内存块,每棵树中存储若干种长度的内存块,每棵树保存的内存块范围如下:
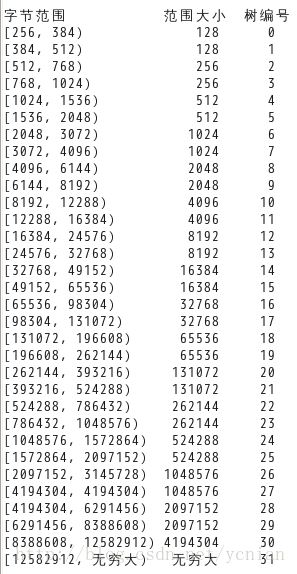
dlmalloc中根据内存块大小计算所在树的编号的宏如下:
[cpp]
- #define compute_tree_index(S, I)\
- {\
- size_t X = S >> TREEBIN_SHIFT; /* TREEBIN_SHIFT的值是8 */ \
- if (X == 0)\
- I = 0;\
- else if (X > 0xFFFF)\
- I = NTREEBINS-1; /* NTREEBINS的值是32 */ \
- else {\
- unsigned int K;\
- __asm__("bsrl %1,%0\n\t" : "=r" (K) : "rm" (X));\
- I = (bindex_t)((K << 1) + ((S >> (K + (TREEBIN_SHIFT-1)) & 1)));\
- }\
- }
如果感兴趣可以采用这个宏计算一下。我们看一下单棵树中保存的空闲内存块,以编号为0的树为例,这棵树中内存块的范围是[256, 384),按照前面规定内存块的大小必须是8的倍数,因此这棵树中保存的内存块长度分别为256, 264, 272, 280, 288, 296, 304, 312, 320, 328, 336, 344, 352, 360, 368, 376,共16种长度,每种长度的内存块作为树中一个节点。这棵树中可能保存了多个相同长度的内存块,这些相同长度的内存块构成了一棵链表,如下图所示:
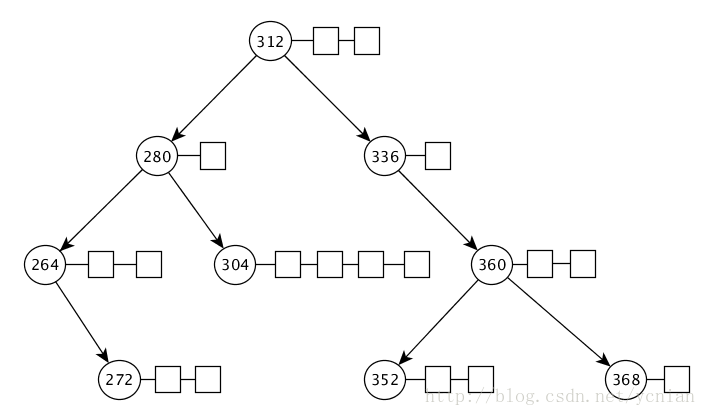
现在回过头来看malloc_tree_chunk中各个字段的含义。
prev_foot表示前一个内存块的大小
head表示本内存块的大小
child表示两个子节点
parent表示父节点
index表示内存块所在树的索引号
fd表示链表中下一个内存块
bk表示链表中前面一个内存块
同样,这个结构中只有head字段保持不变,其他字段都可以供应用程序使用。
现在我们来看一个全局变量_gm_,这是struct malloc_state类型的变量,这个数据结构定义如下:
[cpp]
- struct malloc_state {
- binmap_t smallmap;
- mchunkptr smallbins[(NSMALLBINS+1)*2];
- binmap_t treemap;
- tbinptr treebins[NTREEBINS];
- mchunkptr dv;
- size_t dvsize;
- mchunkptr top;
- size_t topsize;
- char* least_addr;
- size_t trim_check;
- size_t magic;
- size_t footprint;
- #if USE_MAX_ALLOWED_FOOTPRINT
- size_t max_allowed_footprint;
- #endif
- size_t max_footprint;
- flag_t mflags;
- #if USE_LOCKS
- MLOCK_T mutex;
- #endif /* USE_LOCKS */
- msegment seg;
- };
- static struct malloc_state _gm_;
我们重点关注前8个字段。smallbins就是dlmalloc中定义的30条链表(加上长度为0和8的内存块,共32条链表)。smalbins[0]-smallbins[3]共16字节,表示一个malloc_chunk结构,对应长度为0的链表。smalbins[2]-smallbins[5]共16字节,表示一个malloc_chunk结构,对应长度为8的链表,以此类推。可以看到相邻两个malloc_chunk结构有重合,这是因为作为链表使用时,malloc_chunk结构中的prev_foot和head字段没有意义,因此可以重合使用。smallmap是smallbins的位图,某个比特置位表示对应的链表上有空闲内存块,比特清零表示对应的链表为空。treebins表示dlmalloc中32棵树,treemap是treebins的位图,置位表示对应树中有空闲内存块,清零表示对应树为空。dv是一个特殊的内存块,如果dlmalloc中找不到一个合适大小的内存块分配给应用程序,那么dlmalloc会将一个较大的内存块分割成两个较小的内存块,一块给应用程序使用,另外一块保存在dv中。下载再找不到合适大小的内存块时,如果dv大小大于应用程序请求的内存块,dlmalloc会将dv分割成两块,一块给应用程序,另一块仍保存在dv中;如果dv小于应用程序请求的内存块,dlmalloc首先将dv保存在链表或树中,然后挑选另外一个内存块分割,一块给应用程序,另一块保存在dv中。因此dlmalloc分配内存块的原则是先匹配大小,后匹配位置,尽量挑选合适大小的内存块给应用程序,实在找不到合适的内存块时就尽量从同一个位置分割内存块,以提高效率(程序执行的局部性原理)。dvsize就是dv表示内存块的大小。top是另外一个特殊的内存块,表示堆空间中对顶端的内存块。dlmalloc尽量不使用这个内存块,只有在_gm_中没有合适大小的内存块并且没有更大的内存块可供分割时才使用top中的内存。为什么尽量不要使用top呢?因为当top被占用时dlmalloc没办法释放其他空闲内存,dlmalloc收缩堆时必须从高地址向低地址收缩,所以主要高地址的内存被占用,即使堆中有再多的空闲内存也没办法释放。topsize表示top的大小。
[cpp]
- void* dlmalloc(size_t bytes) {
- /*
- Basic algorithm: 算法描述
- If a small request (< 256 bytes minus per-chunk overhead):
- 1. If one exists, use a remainderless chunk in associated smallbin.
- (Remainderless means that there are too few excess bytes to
- represent as a chunk.)
- 2. If it is big enough, use the dv chunk, which is normally the
- chunk adjacent to the one used for the most recent small request.
- 3. If one exists, split the smallest available chunk in a bin,
- saving remainder in dv.
- 4. If it is big enough, use the top chunk.
- 5. If available, get memory from system and use it
- Otherwise, for a large request:
- 1. Find the smallest available binned chunk that fits, and use it
- if it is better fitting than dv chunk, splitting if necessary.
- 2. If better fitting than any binned chunk, use the dv chunk.
- 3. If it is big enough, use the top chunk.
- 4. If request size >= mmap threshold, try to directly mmap this chunk.
- 5. If available, get memory from system and use it
- The ugly goto's here ensure that postaction occurs along all paths.
- */
- if (!PREACTION(gm)) {
- void* mem;
- size_t nb;
- // 如果申请的内存量小于244字节,表示是小块内存.
- if (bytes <= MAX_SMALL_REQUEST) { // 244字节
- bindex_t idx;
- binmap_t smallbits;
- // 修改申请的内存量,考虑malloc_chunk占用的内存,考虑8字节对齐问题.
- nb = (bytes < MIN_REQUEST)? MIN_CHUNK_SIZE : pad_request(bytes);
- // 根据申请的内存大小计算在small bins中的索引号
- idx = small_index(nb);
- // 检查对应的链表或相邻链表中是否有空闲内存块
- smallbits = gm->smallmap >> idx;
- if ((smallbits & 0x3U) != 0) { /* Remainderless fit to a smallbin. */
- mchunkptr b, p;
- // 如果对应链表为空,就使用相邻链表中的内存块.
- idx += ~smallbits & 1; /* Uses next bin if idx empty */
- b = smallbin_at(gm, idx); // 取出这条链表
- p = b->fd; // 这是链表中第一个空闲的内存块,也正是要分配给应用程序使用的内存块.
- assert(chunksize(p) == small_index2size(idx));
- unlink_first_small_chunk(gm, b, p, idx); // 将p从链表中摘除
- // 对内存块做一些设置
- set_inuse_and_pinuse(gm, p, small_index2size(idx));
- mem = chunk2mem(p); // 这是返还给应用程序的内存块的指针
- check_malloced_chunk(gm, mem, nb); // 这是一个检查函数
- goto postaction; // 找到了,返回吧.
- }
- else if (nb > gm->dvsize) { // 申请的内存量比last remainder要大,那么就不能使用last remainder了.
- // 但是其他链表中还有空闲内存块,从其他链表中分配.
- if (smallbits != 0) { /* Use chunk in next nonempty smallbin */
- // 首先需要做的事情就是在small bins中查找一条合适的链表,这条链表非空,并且与请求的内存量差距最小。
- mchunkptr b, p, r;
- size_t rsize;
- bindex_t i;
- binmap_t leftbits = (smallbits << idx) & left_bits(idx2bit(idx));
- binmap_t leastbit = least_bit(leftbits);
- compute_bit2idx(leastbit, i);
- b = smallbin_at(gm, i); // b就是找到的链表
- p = b->fd; // 这是链表中第一个节点,也就是要分配个应用程序的内存块。
- assert(chunksize(p) == small_index2size(i));
- unlink_first_small_chunk(gm, b, p, i); // 将这个节点从链表中摘除.
- rsize = small_index2size(i) - nb; // 去除我们申请的内存后,这个chunk中剩余的空闲内存量.
- /* Fit here cannot be remainderless if 4byte sizes */
- if (SIZE_T_SIZE != 4 && rsize < MIN_CHUNK_SIZE)
- set_inuse_and_pinuse(gm, p, small_index2size(i));
- else { // chunk中剩余的内存量至少是8字节,因此可以继续作为一个独立的内存块使用.
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb);
- r = chunk_plus_offset(p, nb); // 这就是分割nb后剩余的内存构成的新内存块.
- set_size_and_pinuse_of_free_chunk(r, rsize);
- replace_dv(gm, r, rsize); // 用这个内存块替换掉dv,原先的dv保存在合适的链表中.
- }
- mem = chunk2mem(p); // 这是返还给用户程序的缓冲区的指针.
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- } // end if (smallbits != 0)
- // small bins中没有空闲内存块了,因此使用tree bins中的内存块.
- // 由于这个内存块大于我们请求的内存量,因此将这个内存块划分成两个内存块,
- // 一个返回给用户程序使用,另一个设置成dv.
- else if (gm->treemap != 0 && (mem = tmalloc_small(gm, nb)) != 0) {
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- } // end else if (gm->treemap != 0 && (mem = tmalloc_small(gm, nb)) != 0)
- } // end else if (nb > gm->dvsize)
- } // end if (bytes <= MAX_SMALL_REQUEST)
- else if (bytes >= MAX_REQUEST) // 这个值是0xffffffc0 用户申请的内存太大了,直接失败.
- nb = MAX_SIZE_T; /* Too big to allocate. Force failure (in sys alloc) */ // #define MAX_SIZE_T (~(size_t)0)
- else { // 申请的内存量超过248字节,需要从tree bins中分配内存.
- nb = pad_request(bytes); // 修改申请的内存量,考虑8字节对齐,考虑malloc_tree_chunk本身占用的内存空间.
- // 如果tree bins中有空闲的节点 && 成功从tree bins中分配到了内存,那么就使用这块内存.
- if (gm->treemap != 0 && (mem = tmalloc_large(gm, nb)) != 0) {
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- }
- // 如果申请的内存量小于dv,那么就从dv中分割内存.
- if (nb <= gm->dvsize) {
- size_t rsize = gm->dvsize - nb; // 这是分割dv后剩余的内存量.
- mchunkptr p = gm->dv;
- if (rsize >= MIN_CHUNK_SIZE) { /* split dv */ // 剩余的内存还可以作为一个内存块使用
- mchunkptr r = gm->dv = chunk_plus_offset(p, nb); // 这是新的dv
- gm->dvsize = rsize; // 这是新dv的长度
- // 进行一些设置
- set_size_and_pinuse_of_free_chunk(r, rsize);
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb);
- }
- else { /* exhaust dv */ // 剩余的内存太小了,已经不能单独作为一个内存块使用了,那么就将dv全部分给用户程序
- size_t dvs = gm->dvsize; // 这是分给用户程序的内存块的大小
- gm->dvsize = 0;
- gm->dv = 0; // 现在dv为空了
- set_inuse_and_pinuse(gm, p, dvs); // 进行一些设置
- }
- mem = chunk2mem(p); // 这是返回给用户程序的内存区的指针
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- // dv中内存不够了,那么看看top chunk中是否有足够的空闲内存.
- else if (nb < gm->topsize) { /* Split top */ // 如果top chunk中有足够的空闲内存,那么就使用top chunk中的内存.
- size_t rsize = gm->topsize -= nb; // 分配nb后top chunk中剩余的空闲内存.
- mchunkptr p = gm->top;
- mchunkptr r = gm->top = chunk_plus_offset(p, nb); // 这是新的top chunk.
- r->head = rsize | PINUSE_BIT;
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb); // p是分配给用户程序使用的chunk,设置长度和标志.
- mem = chunk2mem(p); // 这是返回给用户程序使用的内存块
- check_top_chunk(gm, gm->top);
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- mem = sys_alloc(gm, nb); // dlmalloc中已经没有足够的空闲内存了,向内核申请内存.
- postaction:
- POSTACTION(gm);
- return mem; // 返回申请到的内存块
- }
- return 0;
- }
这个分配过程还是很麻烦的,因为涉及到多种情况。分析代码流程时记住一个分配顺序就可以了:首选大小合适的内存块,其次分割dv(只有申请的内存量不超过248字节(包括malloc_chunk占用的内存)时才能使用dv),再其次分割一个大的内存块,再其次使用top chunk,最后向内核申请内存。现在分析代码,dlmalloc()首先根据申请的内存量区分了两种情况,因为small bins中内存块的最大长度是248,因此当应用程序请求的内存量不超过AX_SMALL_REQUEST(244字节,因为malloc_chunk结构要占用4字节)时可以从small bins中分配内存;如果超过了244字节那么就需要从tree bins中分配内存。
先看不超过244字节的情况。dlmalloc首先调整了申请的内存量nb = (bytes < MIN_REQUEST)? MIN_CHUNK_SIZE : pad_request(bytes);。pad_request()按照两个因素进行了调整,首先增加malloc_chunk结构占用的4字节,然后将长度按照8字节对齐,因此nb才是dlmalloc需要分配的内存块的大小。然后根据nb计算内存块所在的链表。dlmalloc按照如下顺序分配内存块:
(1)从对应的链表或相邻链表分配
从nb对应的链表中分配内存块是最理想的情况,这种情况下不需要对内存块进行任何操作,直接从链表中取一个内存块给应用程序使用就可以了。如果对应链表为空,可以考虑从相邻链表中分配内存块,相邻链表中内存块长度比对应链表大8个字节,但是dlmalloc中内存块的最小长度是16字节,因此多出来的8字节不能作为一个单独的内存块。这种情况下就没有必要对内存块进行分割了,直接将内存块给应用程序使用就可以了。
(2)从dv分配
如果nb小于dv中内存块大小,那么就将dv分割成两块,一块给应用程序使用,另一块继续作为dv。
(3)从其他链表分配
这种情况下dlmalloc将一个大的内存块分割成两块,一块给应用程序使用,另一块保存在dv中,而dv中原先的内存块保存在对应的链表中。由于内存块大于nb的链表不止一条,那么分割哪条链表中的内存块呢?dlmalloc挑选的是不为空且内存块长度与nb最接近的链表。
(4)从tree bins分配
如果前面三种情况均不能分配到内存,那么dlmalloc就使用tree bins中的内存块。由于tree bins中所有内存块长度都大于nb,因此dlmalloc从tree bins中挑选最小的内存块分割,然后将这个内存块分割成两块,一块给应用程序使用,另一块保存在dv中,而dv中原先的内存块保存在对应的链表中。这种情况是在函数tmalloc_small()中完成的。
(5)从top chunk分配
如果nb小于top chunk中的内存大小,dlmalloc就将top chunk分割成两块,一块给应用程序使用,另一块继续作为top chunk。
(6)向内核申请内存
这是最后一种情况。程序执行到这里说明dlmalloc中没有合适的内存块,只能向内核申请内存了。这是通过sys_alloc()完成的。
现在看超过244字节的情况,这种情况下也需要首先调整内存块大小。由于调整后的长度大于248字节,因此不可能从small bins中找到合适的内存块,并且dlmalloc规定不能使用dv。包含三种情况:
(1)从tree bins中分配内存
如果tree bins中正好包含长度是nb的内存块,那么直接给应用程序使用就行了。如果没有长度是nb的内存块,那么就需要将一块更大的内存块分割成两块,一块给应用程序使用,另一块保存在small bins中(如果长度不超过248字节)或tree bins中(长度超过248字节)。这是在函数tmalloc_large()中实现的。
(2)从top chunk分配内存
(3)向内核申请内存
这里就不进一步讲解tmalloc_small()和tmalloc_large()了,因为这两个函数原理很简单,就是从一棵树中挑选一个合适的内存块,然后分割成两块,一块给应用程序使用,另一块继续保存在dlmalloc中。下面详细分析dlmalloc向内核申请内存的过程。向内核申请内存时首先要考虑的问题是向内核申请多少内存?如果只满足本次需求,那么很可能应用程序下次调用malloc()时dlmalloc还需要向内核申请内存。由于系统调用效率比较低,因此比较好的办法是dlmalloc向内核多申请一些内存,这样下次就不必再向内核申请了。看下面一个数据结构:
[cpp]
- struct malloc_params {
- size_t magic; // 就是一个简单的魔数
- size_t page_size; // 这是内存页大小
- size_t granularity; // 每次向内核申请内存的最小量,一般情况下就是内存页的长度.
- size_t mmap_threshold; // 这是一个阈值阈值,超过这个阈值的内存请求直接调用mmap().
- size_t trim_threshold; // 这是收缩堆的阈值,top chunk的长度超过这个值时会收缩堆.
- flag_t default_mflags; // 这是一些标志
- };
这是dlmalloc向内核申请内存时使用的一个数据结构,我们注释了数据结构中各个字段的含义,因此dlmalloc每次至少向内核申请4kb内存。
[cpp]
- static void* sys_alloc(mstate m, size_t nb) {
- char* tbase = CMFAIL; // CMFAIL表示申请内存失败了.
- size_t tsize = 0;
- flag_t mmap_flag = 0;
- init_mparams(); // 这是一个初始化函数,这个函数在初始化全局变量mparams.
- /* Directly map large chunks */
- // 应用程序申请的内存量超过了256kb,直接使用mmap(2)申请内存.
- if (use_mmap(m) && nb >= mparams.mmap_threshold) {
- void* mem = mmap_alloc(m, nb); // 使用mmap(2)向系统申请内存
- if (mem != 0)
- // 这种情况下dlmalloc不管理申请到的内存
- return mem; // 直接返回申请到的内存
- }
- #if USE_MAX_ALLOWED_FOOTPRINT // 这个宏是0,跳过下面这段代码.
- /* Make sure the footprint doesn't grow past max_allowed_footprint.
- * This covers all cases except for where we need to page align, below.
- */
- {
- size_t new_footprint = m->footprint +
- granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- if (new_footprint <= m->footprint || /* Check for wrap around 0 */
- new_footprint > m->max_allowed_footprint)
- return 0;
- }
- #endif
- // 如果申请的内存不超过256kb,或者虽然超过256kb了但是mmap()失败了
- // 会执行到下面的代码.
- /*
- Try getting memory in any of three ways (in most-preferred to
- least-preferred order):
- 1. A call to MORECORE that can normally contiguously extend memory.
- (disabled if not MORECORE_CONTIGUOUS or not HAVE_MORECORE or
- or main space is mmapped or a previous contiguous call failed)
- 2. A call to MMAP new space (disabled if not HAVE_MMAP).
- Note that under the default settings, if MORECORE is unable to
- fulfill a request, and HAVE_MMAP is true, then mmap is
- used as a noncontiguous system allocator. This is a useful backup
- strategy for systems with holes in address spaces -- in this case
- sbrk cannot contiguously expand the heap, but mmap may be able to
- find space.
- 3. A call to MORECORE that cannot usually contiguously extend memory.
- (disabled if not HAVE_MORECORE)
- */
- #define is_mmapped_segment(S) ((S)->sflags & IS_MMAPPED_BIT)
- #define is_extern_segment(S) ((S)->sflags & EXTERN_BIT)
- // 通过brk()扩展内存,堆是连续的.
- if (MORECORE_CONTIGUOUS && !use_noncontiguous(m)) {
- char* br = CMFAIL;
- // 查找包含top chunk的segment. segment到底是什么呢????
- msegmentptr ss = (m->top == 0)? 0 : segment_holding(m, (char*)m->top);
- size_t asize = 0;
- ACQUIRE_MORECORE_LOCK();
- // 如果还没有top chunk,或者top chunk不保存在任何segment中.
- // 这是第一次执行brk操作,先看看这种情况.
- if (ss == 0) { /* First time through or recovery */
- // char* base = (char*)sbrk(0); 通过向sbrk()传入0可以获取进程中堆的结束地址
- char* base = (char*)CALL_MORECORE(0);
- if (base != CMFAIL) {
- // 调整了向内核申请的内存量.
- asize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- /* Adjust to end on a page boundary */
- if (!is_page_aligned(base)) { // 而且堆结束地址需要按照内存页对齐
- asize += (page_align((size_t)base) - (size_t)base);
- #if USE_MAX_ALLOWED_FOOTPRINT
- /* If the alignment pushes us over max_allowed_footprint,
- * poison the upcoming call to MORECORE and continue.
- */
- {
- size_t new_footprint = m->footprint + asize;
- if (new_footprint <= m->footprint || /* Check for wrap around 0 */
- new_footprint > m->max_allowed_footprint) {
- asize = HALF_MAX_SIZE_T;
- }
- }
- #endif
- } // end if (!is_page_aligned(base))
- /* Can't call MORECORE if size is negative when treated as signed */
- // 这里调用sbkr(2)向内核申请内存了.
- if (asize < HALF_MAX_SIZE_T &&
- // sbrk()返回修改前堆的结束地址.
- (br = (char*)(CALL_MORECORE(asize))) == base) {
- tbase = base; // 这是堆修改前的地址
- tsize = asize; // 这是长度
- }
- } // end if (base != CMFAIL)
- }
- else { // 已经有top chunk了,除去top chunk中的空间,dl还需要申请这么多空间.
- /* Subtract out existing available top space from MORECORE request. */
- asize = granularity_align(nb - m->topsize + TOP_FOOT_SIZE + SIZE_T_ONE);
- /* Use mem here only if it did continuously extend old space */
- // 这里调用sbrk(2)向内核申请内存了.
- if (asize < HALF_MAX_SIZE_T &&
- (br = (char*)(CALL_MORECORE(asize))) == ss->base+ss->size) {
- tbase = br;
- tsize = asize;
- }
- } // end if (ss == 0)
- // 内存分配过程中中间步骤失败了.
- if (tbase == CMFAIL) { /* Cope with partial failure */
- if (br != CMFAIL) { /* Try to use/extend the space we did get */
- if (asize < HALF_MAX_SIZE_T &&
- asize < nb + TOP_FOOT_SIZE + SIZE_T_ONE) {
- size_t esize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE - asize);
- if (esize < HALF_MAX_SIZE_T) {
- char* end = (char*)CALL_MORECORE(esize); // 仍然在调用brk
- if (end != CMFAIL)
- asize += esize;
- else { /* Can't use; try to release */
- CALL_MORECORE(-asize);
- br = CMFAIL;
- }
- }
- }
- }
- if (br != CMFAIL) { /* Use the space we did get */
- tbase = br;
- tsize = asize;
- }
- else
- disable_contiguous(m); /* Don't try contiguous path in the future */
- } // end if (tbase == CMFAIL)
- RELEASE_MORECORE_LOCK();
- } // end if (MORECORE_CONTIGUOUS && !use_noncontiguous(m))
- // 前面申请内存失败了
- if (HAVE_MMAP && tbase == CMFAIL) { /* Try MMAP */
- size_t req = nb + TOP_FOOT_SIZE + SIZE_T_ONE;
- size_t rsize = granularity_align(req);
- if (rsize > nb) { /* Fail if wraps around zero */
- char* mp = (char*)(CALL_MMAP(rsize)); // 通过mmap(2)方式申请内存.
- if (mp != CMFAIL) {
- tbase = mp;
- tsize = rsize;
- mmap_flag = IS_MMAPPED_BIT;
- }
- }
- } // end if (HAVE_MMAP && tbase == CMFAIL)
- // 通过brk()申请非连续内存,Linux系统中堆应该是连续的,不存在不连续的堆.
- if (HAVE_MORECORE && tbase == CMFAIL) { /* Try noncontiguous MORECORE */
- size_t asize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- if (asize < HALF_MAX_SIZE_T) {
- char* br = CMFAIL;
- char* end = CMFAIL;
- ACQUIRE_MORECORE_LOCK();
- br = (char*)(CALL_MORECORE(asize));
- end = (char*)(CALL_MORECORE(0));
- RELEASE_MORECORE_LOCK();
- if (br != CMFAIL && end != CMFAIL && br < end) {
- size_t ssize = end - br;
- if (ssize > nb + TOP_FOOT_SIZE) {
- tbase = br;
- tsize = ssize;
- }
- }
- }
- } // end if (HAVE_MORECORE && tbase == CMFAIL)
- // tbase != CMFAIL 表示申请内存成功了,现在进行一些设置.
- if (tbase != CMFAIL) {
- if ((m->footprint += tsize) > m->max_footprint)
- m->max_footprint = m->footprint;
- // 如果malloc_state结构还没有初始化,那么先对malloc_state结构初始化.
- if (!is_initialized(m)) { /* first-time initialization */
- m->seg.base = m->least_addr = tbase; // 这是起始地址
- m->seg.size = tsize; // 这是长度
- m->seg.sflags = mmap_flag; // 标志,是否通过mmap()创建的.
- m->magic = mparams.magic; // magic
- init_bins(m); // 这个函数在初始化small bins
- if (is_global(m))
- init_top(m, (mchunkptr)tbase, tsize - TOP_FOOT_SIZE);
- else {
- /* Offset top by embedded malloc_state */
- mchunkptr mn = next_chunk(mem2chunk(m));
- init_top(m, mn, (size_t)((tbase + tsize) - (char*)mn) -TOP_FOOT_SIZE);
- }
- }
- else { // 尝试合并
- /* Try to merge with an existing segment */
- msegmentptr sp = &m->seg; // 这是malloc_state中第一个segment.
- while (sp != 0 && tbase != sp->base + sp->size)
- sp = sp->next; // 查找连续的segment.
- if (sp != 0 &&
- !is_extern_segment(sp) &&
- (sp->sflags & IS_MMAPPED_BIT) == mmap_flag &&
- segment_holds(sp, m->top)) { /* append */ // 新申请的内存跟系统中某个segment连续.
- sp->size += tsize; // 修改这个segment的长度
- init_top(m, m->top, m->topsize + tsize);
- }
- else { // 新申请的内存跟系统中已经存在的segment不连续.
- if (tbase < m->least_addr)
- m->least_addr = tbase; // 设置新的least_addr,这个值只供数据检查使用.
- sp = &m->seg; // 这是存放segment结构的链表头节点
- while (sp != 0 && sp->base != tbase + tsize)
- sp = sp->next; // 查找新申请的内存是否位于某个segment之前.
- if (sp != 0 &&
- !is_extern_segment(sp) &&
- (sp->sflags & IS_MMAPPED_BIT) == mmap_flag) {
- char* oldbase = sp->base; // 这是segment原先的起始地址
- sp->base = tbase; // 重新设置新的起始地址和长度
- sp->size += tsize;
- return prepend_alloc(m, tbase, oldbase, nb);
- }
- else
- add_segment(m, tbase, tsize, mmap_flag); // 将一个新的segment添加到链表中.
- }
- } // end if (!is_initialized(m)))
- // 从top chunk中分配内存.
- if (nb < m->topsize) { /* Allocate from new or extended top space */
- size_t rsize = m->topsize -= nb; // 这是top chunk中剩余的空闲内存量
- mchunkptr p = m->top; // 这是top chunk的起始地址
- mchunkptr r = m->top = chunk_plus_offset(p, nb); // 将这里看作一个新的chunk,这是新的top chunk.
- r->head = rsize | PINUSE_BIT; // 这是top chunk中的内存量
- set_size_and_pinuse_of_inuse_chunk(m, p, nb); // 设置供用户程序使用的内存块
- check_top_chunk(m, m->top);
- check_malloced_chunk(m, chunk2mem(p), nb);
- return chunk2mem(p); // 返回内存块的地址给应用程序.
- }
- } // end if (tbase != CMFAIL)
- MALLOC_FAILURE_ACTION;
- return 0;
- }
这个函数也相当复杂,因为dlmalloc适用于各种操作系统,每种系统申请内存的方式不一定相同。Linux系统包含两种方式:(1)brk()扩展堆;(2)mmap()映射一块新的内存区。malloc_params结构中的mmap_threshold是一个阈值,默认值是256kb,当申请的内存量超过这个阈值时dlmalloc首先mmap()方式映射一块单独的内存区域,如果mmap()失败了dlmalloc尝试brk()方式扩展堆。如果申请的内存量没有超过这个阈值dlmalloc首先brk()方式,如果brk()失败了dlmalloc再尝试mmap()方式。
[cpp]
- void* dlmalloc(size_t bytes) {
- /*
- Basic algorithm: 算法描述
- If a small request (< 256 bytes minus per-chunk overhead):
- 1. If one exists, use a remainderless chunk in associated smallbin.
- (Remainderless means that there are too few excess bytes to
- represent as a chunk.)
- 2. If it is big enough, use the dv chunk, which is normally the
- chunk adjacent to the one used for the most recent small request.
- 3. If one exists, split the smallest available chunk in a bin,
- saving remainder in dv.
- 4. If it is big enough, use the top chunk.
- 5. If available, get memory from system and use it
- Otherwise, for a large request:
- 1. Find the smallest available binned chunk that fits, and use it
- if it is better fitting than dv chunk, splitting if necessary.
- 2. If better fitting than any binned chunk, use the dv chunk.
- 3. If it is big enough, use the top chunk.
- 4. If request size >= mmap threshold, try to directly mmap this chunk.
- 5. If available, get memory from system and use it
- The ugly goto's here ensure that postaction occurs along all paths.
- */
- if (!PREACTION(gm)) {
- void* mem;
- size_t nb;
- // 如果申请的内存量小于244字节,表示是小块内存.
- if (bytes <= MAX_SMALL_REQUEST) { // 244字节
- bindex_t idx;
- binmap_t smallbits;
- // 修改申请的内存量,考虑malloc_chunk占用的内存,考虑8字节对齐问题.
- nb = (bytes < MIN_REQUEST)? MIN_CHUNK_SIZE : pad_request(bytes);
- // 根据申请的内存大小计算在small bins中的索引号
- idx = small_index(nb);
- // 检查对应的链表或相邻链表中是否有空闲内存块
- smallbits = gm->smallmap >> idx;
- if ((smallbits & 0x3U) != 0) { /* Remainderless fit to a smallbin. */
- mchunkptr b, p;
- // 如果对应链表为空,就使用相邻链表中的内存块.
- idx += ~smallbits & 1; /* Uses next bin if idx empty */
- b = smallbin_at(gm, idx); // 取出这条链表
- p = b->fd; // 这是链表中第一个空闲的内存块,也正是要分配给应用程序使用的内存块.
- assert(chunksize(p) == small_index2size(idx));
- unlink_first_small_chunk(gm, b, p, idx); // 将p从链表中摘除
- // 对内存块做一些设置
- set_inuse_and_pinuse(gm, p, small_index2size(idx));
- mem = chunk2mem(p); // 这是返还给应用程序的内存块的指针
- check_malloced_chunk(gm, mem, nb); // 这是一个检查函数
- goto postaction; // 找到了,返回吧.
- }
- else if (nb > gm->dvsize) { // 申请的内存量比last remainder要大,那么就不能使用last remainder了.
- // 但是其他链表中还有空闲内存块,从其他链表中分配.
- if (smallbits != 0) { /* Use chunk in next nonempty smallbin */
- // 首先需要做的事情就是在small bins中查找一条合适的链表,这条链表非空,并且与请求的内存量差距最小。
- mchunkptr b, p, r;
- size_t rsize;
- bindex_t i;
- binmap_t leftbits = (smallbits << idx) & left_bits(idx2bit(idx));
- binmap_t leastbit = least_bit(leftbits);
- compute_bit2idx(leastbit, i);
- b = smallbin_at(gm, i); // b就是找到的链表
- p = b->fd; // 这是链表中第一个节点,也就是要分配个应用程序的内存块。
- assert(chunksize(p) == small_index2size(i));
- unlink_first_small_chunk(gm, b, p, i); // 将这个节点从链表中摘除.
- rsize = small_index2size(i) - nb; // 去除我们申请的内存后,这个chunk中剩余的空闲内存量.
- /* Fit here cannot be remainderless if 4byte sizes */
- if (SIZE_T_SIZE != 4 && rsize < MIN_CHUNK_SIZE)
- set_inuse_and_pinuse(gm, p, small_index2size(i));
- else { // chunk中剩余的内存量至少是8字节,因此可以继续作为一个独立的内存块使用.
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb);
- r = chunk_plus_offset(p, nb); // 这就是分割nb后剩余的内存构成的新内存块.
- set_size_and_pinuse_of_free_chunk(r, rsize);
- replace_dv(gm, r, rsize); // 用这个内存块替换掉dv,原先的dv保存在合适的链表中.
- }
- mem = chunk2mem(p); // 这是返还给用户程序的缓冲区的指针.
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- } // end if (smallbits != 0)
- // small bins中没有空闲内存块了,因此使用tree bins中的内存块.
- // 由于这个内存块大于我们请求的内存量,因此将这个内存块划分成两个内存块,
- // 一个返回给用户程序使用,另一个设置成dv.
- else if (gm->treemap != 0 && (mem = tmalloc_small(gm, nb)) != 0) {
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- } // end else if (gm->treemap != 0 && (mem = tmalloc_small(gm, nb)) != 0)
- } // end else if (nb > gm->dvsize)
- } // end if (bytes <= MAX_SMALL_REQUEST)
- else if (bytes >= MAX_REQUEST) // 这个值是0xffffffc0 用户申请的内存太大了,直接失败.
- nb = MAX_SIZE_T; /* Too big to allocate. Force failure (in sys alloc) */ // #define MAX_SIZE_T (~(size_t)0)
- else { // 申请的内存量超过248字节,需要从tree bins中分配内存.
- nb = pad_request(bytes); // 修改申请的内存量,考虑8字节对齐,考虑malloc_tree_chunk本身占用的内存空间.
- // 如果tree bins中有空闲的节点 && 成功从tree bins中分配到了内存,那么就使用这块内存.
- if (gm->treemap != 0 && (mem = tmalloc_large(gm, nb)) != 0) {
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- }
- // 如果申请的内存量小于dv,那么就从dv中分割内存.
- if (nb <= gm->dvsize) {
- size_t rsize = gm->dvsize - nb; // 这是分割dv后剩余的内存量.
- mchunkptr p = gm->dv;
- if (rsize >= MIN_CHUNK_SIZE) { /* split dv */ // 剩余的内存还可以作为一个内存块使用
- mchunkptr r = gm->dv = chunk_plus_offset(p, nb); // 这是新的dv
- gm->dvsize = rsize; // 这是新dv的长度
- // 进行一些设置
- set_size_and_pinuse_of_free_chunk(r, rsize);
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb);
- }
- else { /* exhaust dv */ // 剩余的内存太小了,已经不能单独作为一个内存块使用了,那么就将dv全部分给用户程序
- size_t dvs = gm->dvsize; // 这是分给用户程序的内存块的大小
- gm->dvsize = 0;
- gm->dv = 0; // 现在dv为空了
- set_inuse_and_pinuse(gm, p, dvs); // 进行一些设置
- }
- mem = chunk2mem(p); // 这是返回给用户程序的内存区的指针
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- // dv中内存不够了,那么看看top chunk中是否有足够的空闲内存.
- else if (nb < gm->topsize) { /* Split top */ // 如果top chunk中有足够的空闲内存,那么就使用top chunk中的内存.
- size_t rsize = gm->topsize -= nb; // 分配nb后top chunk中剩余的空闲内存.
- mchunkptr p = gm->top;
- mchunkptr r = gm->top = chunk_plus_offset(p, nb); // 这是新的top chunk.
- r->head = rsize | PINUSE_BIT;
- set_size_and_pinuse_of_inuse_chunk(gm, p, nb); // p是分配给用户程序使用的chunk,设置长度和标志.
- mem = chunk2mem(p); // 这是返回给用户程序使用的内存块
- check_top_chunk(gm, gm->top);
- check_malloced_chunk(gm, mem, nb);
- goto postaction;
- }
- mem = sys_alloc(gm, nb); // dlmalloc中已经没有足够的空闲内存了,向内核申请内存.
- postaction:
- POSTACTION(gm);
- return mem; // 返回申请到的内存块
- }
- return 0;
- }
这个分配过程还是很麻烦的,因为涉及到多种情况。分析代码流程时记住一个分配顺序就可以了:首选大小合适的内存块,其次分割dv(只有申请的内存量不超过248字节(包括malloc_chunk占用的内存)时才能使用dv),再其次分割一个大的内存块,再其次使用top chunk,最后向内核申请内存。现在分析代码,dlmalloc()首先根据申请的内存量区分了两种情况,因为small bins中内存块的最大长度是248,因此当应用程序请求的内存量不超过AX_SMALL_REQUEST(244字节,因为malloc_chunk结构要占用4字节)时可以从small bins中分配内存;如果超过了244字节那么就需要从tree bins中分配内存。
先看不超过244字节的情况。dlmalloc首先调整了申请的内存量nb = (bytes < MIN_REQUEST)? MIN_CHUNK_SIZE : pad_request(bytes);。pad_request()按照两个因素进行了调整,首先增加malloc_chunk结构占用的4字节,然后将长度按照8字节对齐,因此nb才是dlmalloc需要分配的内存块的大小。然后根据nb计算内存块所在的链表。dlmalloc按照如下顺序分配内存块:
(1)从对应的链表或相邻链表分配
从nb对应的链表中分配内存块是最理想的情况,这种情况下不需要对内存块进行任何操作,直接从链表中取一个内存块给应用程序使用就可以了。如果对应链表为空,可以考虑从相邻链表中分配内存块,相邻链表中内存块长度比对应链表大8个字节,但是dlmalloc中内存块的最小长度是16字节,因此多出来的8字节不能作为一个单独的内存块。这种情况下就没有必要对内存块进行分割了,直接将内存块给应用程序使用就可以了。
(2)从dv分配
如果nb小于dv中内存块大小,那么就将dv分割成两块,一块给应用程序使用,另一块继续作为dv。
(3)从其他链表分配
这种情况下dlmalloc将一个大的内存块分割成两块,一块给应用程序使用,另一块保存在dv中,而dv中原先的内存块保存在对应的链表中。由于内存块大于nb的链表不止一条,那么分割哪条链表中的内存块呢?dlmalloc挑选的是不为空且内存块长度与nb最接近的链表。
(4)从tree bins分配
如果前面三种情况均不能分配到内存,那么dlmalloc就使用tree bins中的内存块。由于tree bins中所有内存块长度都大于nb,因此dlmalloc从tree bins中挑选最小的内存块分割,然后将这个内存块分割成两块,一块给应用程序使用,另一块保存在dv中,而dv中原先的内存块保存在对应的链表中。这种情况是在函数tmalloc_small()中完成的。
(5)从top chunk分配
如果nb小于top chunk中的内存大小,dlmalloc就将top chunk分割成两块,一块给应用程序使用,另一块继续作为top chunk。
(6)向内核申请内存
这是最后一种情况。程序执行到这里说明dlmalloc中没有合适的内存块,只能向内核申请内存了。这是通过sys_alloc()完成的。
现在看超过244字节的情况,这种情况下也需要首先调整内存块大小。由于调整后的长度大于248字节,因此不可能从small bins中找到合适的内存块,并且dlmalloc规定不能使用dv。包含三种情况:
(1)从tree bins中分配内存
如果tree bins中正好包含长度是nb的内存块,那么直接给应用程序使用就行了。如果没有长度是nb的内存块,那么就需要将一块更大的内存块分割成两块,一块给应用程序使用,另一块保存在small bins中(如果长度不超过248字节)或tree bins中(长度超过248字节)。这是在函数tmalloc_large()中实现的。
(2)从top chunk分配内存
(3)向内核申请内存
这里就不进一步讲解tmalloc_small()和tmalloc_large()了,因为这两个函数原理很简单,就是从一棵树中挑选一个合适的内存块,然后分割成两块,一块给应用程序使用,另一块继续保存在dlmalloc中。下面详细分析dlmalloc向内核申请内存的过程。向内核申请内存时首先要考虑的问题是向内核申请多少内存?如果只满足本次需求,那么很可能应用程序下次调用malloc()时dlmalloc还需要向内核申请内存。由于系统调用效率比较低,因此比较好的办法是dlmalloc向内核多申请一些内存,这样下次就不必再向内核申请了。看下面一个数据结构:
[cpp]
- struct malloc_params {
- size_t magic; // 就是一个简单的魔数
- size_t page_size; // 这是内存页大小
- size_t granularity; // 每次向内核申请内存的最小量,一般情况下就是内存页的长度.
- size_t mmap_threshold; // 这是一个阈值阈值,超过这个阈值的内存请求直接调用mmap().
- size_t trim_threshold; // 这是收缩堆的阈值,top chunk的长度超过这个值时会收缩堆.
- flag_t default_mflags; // 这是一些标志
- };
这是dlmalloc向内核申请内存时使用的一个数据结构,我们注释了数据结构中各个字段的含义,因此dlmalloc每次至少向内核申请4kb内存。
[cpp]
- static void* sys_alloc(mstate m, size_t nb) {
- char* tbase = CMFAIL; // CMFAIL表示申请内存失败了.
- size_t tsize = 0;
- flag_t mmap_flag = 0;
- init_mparams(); // 这是一个初始化函数,这个函数在初始化全局变量mparams.
- /* Directly map large chunks */
- // 应用程序申请的内存量超过了256kb,直接使用mmap(2)申请内存.
- if (use_mmap(m) && nb >= mparams.mmap_threshold) {
- void* mem = mmap_alloc(m, nb); // 使用mmap(2)向系统申请内存
- if (mem != 0)
- // 这种情况下dlmalloc不管理申请到的内存
- return mem; // 直接返回申请到的内存
- }
- #if USE_MAX_ALLOWED_FOOTPRINT // 这个宏是0,跳过下面这段代码.
- /* Make sure the footprint doesn't grow past max_allowed_footprint.
- * This covers all cases except for where we need to page align, below.
- */
- {
- size_t new_footprint = m->footprint +
- granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- if (new_footprint <= m->footprint || /* Check for wrap around 0 */
- new_footprint > m->max_allowed_footprint)
- return 0;
- }
- #endif
- // 如果申请的内存不超过256kb,或者虽然超过256kb了但是mmap()失败了
- // 会执行到下面的代码.
- /*
- Try getting memory in any of three ways (in most-preferred to
- least-preferred order):
- 1. A call to MORECORE that can normally contiguously extend memory.
- (disabled if not MORECORE_CONTIGUOUS or not HAVE_MORECORE or
- or main space is mmapped or a previous contiguous call failed)
- 2. A call to MMAP new space (disabled if not HAVE_MMAP).
- Note that under the default settings, if MORECORE is unable to
- fulfill a request, and HAVE_MMAP is true, then mmap is
- used as a noncontiguous system allocator. This is a useful backup
- strategy for systems with holes in address spaces -- in this case
- sbrk cannot contiguously expand the heap, but mmap may be able to
- find space.
- 3. A call to MORECORE that cannot usually contiguously extend memory.
- (disabled if not HAVE_MORECORE)
- */
- #define is_mmapped_segment(S) ((S)->sflags & IS_MMAPPED_BIT)
- #define is_extern_segment(S) ((S)->sflags & EXTERN_BIT)
- // 通过brk()扩展内存,堆是连续的.
- if (MORECORE_CONTIGUOUS && !use_noncontiguous(m)) {
- char* br = CMFAIL;
- // 查找包含top chunk的segment. segment到底是什么呢????
- msegmentptr ss = (m->top == 0)? 0 : segment_holding(m, (char*)m->top);
- size_t asize = 0;
- ACQUIRE_MORECORE_LOCK();
- // 如果还没有top chunk,或者top chunk不保存在任何segment中.
- // 这是第一次执行brk操作,先看看这种情况.
- if (ss == 0) { /* First time through or recovery */
- // char* base = (char*)sbrk(0); 通过向sbrk()传入0可以获取进程中堆的结束地址
- char* base = (char*)CALL_MORECORE(0);
- if (base != CMFAIL) {
- // 调整了向内核申请的内存量.
- asize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- /* Adjust to end on a page boundary */
- if (!is_page_aligned(base)) { // 而且堆结束地址需要按照内存页对齐
- asize += (page_align((size_t)base) - (size_t)base);
- #if USE_MAX_ALLOWED_FOOTPRINT
- /* If the alignment pushes us over max_allowed_footprint,
- * poison the upcoming call to MORECORE and continue.
- */
- {
- size_t new_footprint = m->footprint + asize;
- if (new_footprint <= m->footprint || /* Check for wrap around 0 */
- new_footprint > m->max_allowed_footprint) {
- asize = HALF_MAX_SIZE_T;
- }
- }
- #endif
- } // end if (!is_page_aligned(base))
- /* Can't call MORECORE if size is negative when treated as signed */
- // 这里调用sbkr(2)向内核申请内存了.
- if (asize < HALF_MAX_SIZE_T &&
- // sbrk()返回修改前堆的结束地址.
- (br = (char*)(CALL_MORECORE(asize))) == base) {
- tbase = base; // 这是堆修改前的地址
- tsize = asize; // 这是长度
- }
- } // end if (base != CMFAIL)
- }
- else { // 已经有top chunk了,除去top chunk中的空间,dl还需要申请这么多空间.
- /* Subtract out existing available top space from MORECORE request. */
- asize = granularity_align(nb - m->topsize + TOP_FOOT_SIZE + SIZE_T_ONE);
- /* Use mem here only if it did continuously extend old space */
- // 这里调用sbrk(2)向内核申请内存了.
- if (asize < HALF_MAX_SIZE_T &&
- (br = (char*)(CALL_MORECORE(asize))) == ss->base+ss->size) {
- tbase = br;
- tsize = asize;
- }
- } // end if (ss == 0)
- // 内存分配过程中中间步骤失败了.
- if (tbase == CMFAIL) { /* Cope with partial failure */
- if (br != CMFAIL) { /* Try to use/extend the space we did get */
- if (asize < HALF_MAX_SIZE_T &&
- asize < nb + TOP_FOOT_SIZE + SIZE_T_ONE) {
- size_t esize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE - asize);
- if (esize < HALF_MAX_SIZE_T) {
- char* end = (char*)CALL_MORECORE(esize); // 仍然在调用brk
- if (end != CMFAIL)
- asize += esize;
- else { /* Can't use; try to release */
- CALL_MORECORE(-asize);
- br = CMFAIL;
- }
- }
- }
- }
- if (br != CMFAIL) { /* Use the space we did get */
- tbase = br;
- tsize = asize;
- }
- else
- disable_contiguous(m); /* Don't try contiguous path in the future */
- } // end if (tbase == CMFAIL)
- RELEASE_MORECORE_LOCK();
- } // end if (MORECORE_CONTIGUOUS && !use_noncontiguous(m))
- // 前面申请内存失败了
- if (HAVE_MMAP && tbase == CMFAIL) { /* Try MMAP */
- size_t req = nb + TOP_FOOT_SIZE + SIZE_T_ONE;
- size_t rsize = granularity_align(req);
- if (rsize > nb) { /* Fail if wraps around zero */
- char* mp = (char*)(CALL_MMAP(rsize)); // 通过mmap(2)方式申请内存.
- if (mp != CMFAIL) {
- tbase = mp;
- tsize = rsize;
- mmap_flag = IS_MMAPPED_BIT;
- }
- }
- } // end if (HAVE_MMAP && tbase == CMFAIL)
- // 通过brk()申请非连续内存,Linux系统中堆应该是连续的,不存在不连续的堆.
- if (HAVE_MORECORE && tbase == CMFAIL) { /* Try noncontiguous MORECORE */
- size_t asize = granularity_align(nb + TOP_FOOT_SIZE + SIZE_T_ONE);
- if (asize < HALF_MAX_SIZE_T) {
- char* br = CMFAIL;
- char* end = CMFAIL;
- ACQUIRE_MORECORE_LOCK();
- br = (char*)(CALL_MORECORE(asize));
- end = (char*)(CALL_MORECORE(0));
- RELEASE_MORECORE_LOCK();
- if (br != CMFAIL && end != CMFAIL && br < end) {
- size_t ssize = end - br;
- if (ssize > nb + TOP_FOOT_SIZE) {
- tbase = br;
- tsize = ssize;
- }
- }
- }
- } // end if (HAVE_MORECORE && tbase == CMFAIL)
- // tbase != CMFAIL 表示申请内存成功了,现在进行一些设置.
- if (tbase != CMFAIL) {
- if ((m->footprint += tsize) > m->max_footprint)
- m->max_footprint = m->footprint;
- // 如果malloc_state结构还没有初始化,那么先对malloc_state结构初始化.
- if (!is_initialized(m)) { /* first-time initialization */
- m->seg.base = m->least_addr = tbase; // 这是起始地址
- m->seg.size = tsize; // 这是长度
- m->seg.sflags = mmap_flag; // 标志,是否通过mmap()创建的.
- m->magic = mparams.magic; // magic
- init_bins(m); // 这个函数在初始化small bins
- if (is_global(m))
- init_top(m, (mchunkptr)tbase, tsize - TOP_FOOT_SIZE);
- else {
- /* Offset top by embedded malloc_state */
- mchunkptr mn = next_chunk(mem2chunk(m));
- init_top(m, mn, (size_t)((tbase + tsize) - (char*)mn) -TOP_FOOT_SIZE);
- }
- }
- else { // 尝试合并
- /* Try to merge with an existing segment */
- msegmentptr sp = &m->seg; // 这是malloc_state中第一个segment.
- while (sp != 0 && tbase != sp->base + sp->size)
- sp = sp->next; // 查找连续的segment.
- if (sp != 0 &&
- !is_extern_segment(sp) &&
- (sp->sflags & IS_MMAPPED_BIT) == mmap_flag &&
- segment_holds(sp, m->top)) { /* append */ // 新申请的内存跟系统中某个segment连续.
- sp->size += tsize; // 修改这个segment的长度
- init_top(m, m->top, m->topsize + tsize);
- }
- else { // 新申请的内存跟系统中已经存在的segment不连续.
- if (tbase < m->least_addr)
- m->least_addr = tbase; // 设置新的least_addr,这个值只供数据检查使用.
- sp = &m->seg; // 这是存放segment结构的链表头节点
- while (sp != 0 && sp->base != tbase + tsize)
- sp = sp->next; // 查找新申请的内存是否位于某个segment之前.
- if (sp != 0 &&
- !is_extern_segment(sp) &&
- (sp->sflags & IS_MMAPPED_BIT) == mmap_flag) {
- char* oldbase = sp->base; // 这是segment原先的起始地址
- sp->base = tbase; // 重新设置新的起始地址和长度
- sp->size += tsize;
- return prepend_alloc(m, tbase, oldbase, nb);
- }
- else
- add_segment(m, tbase, tsize, mmap_flag); // 将一个新的segment添加到链表中.
- }
- } // end if (!is_initialized(m)))
- // 从top chunk中分配内存.
- if (nb < m->topsize) { /* Allocate from new or extended top space */
- size_t rsize = m->topsize -= nb; // 这是top chunk中剩余的空闲内存量
- mchunkptr p = m->top; // 这是top chunk的起始地址
- mchunkptr r = m->top = chunk_plus_offset(p, nb); // 将这里看作一个新的chunk,这是新的top chunk.
- r->head = rsize | PINUSE_BIT; // 这是top chunk中的内存量
- set_size_and_pinuse_of_inuse_chunk(m, p, nb); // 设置供用户程序使用的内存块
- check_top_chunk(m, m->top);
- check_malloced_chunk(m, chunk2mem(p), nb);
- return chunk2mem(p); // 返回内存块的地址给应用程序.
- }
- } // end if (tbase != CMFAIL)
- MALLOC_FAILURE_ACTION;
- return 0;
- }
这个函数也相当复杂,因为dlmalloc适用于各种操作系统,每种系统申请内存的方式不一定相同。Linux系统包含两种方式:(1)brk()扩展堆;(2)mmap()映射一块新的内存区。malloc_params结构中的mmap_threshold是一个阈值,默认值是256kb,当申请的内存量超过这个阈值时dlmalloc首先mmap()方式映射一块单独的内存区域,如果mmap()失败了dlmalloc尝试brk()方式扩展堆。如果申请的内存量没有超过这个阈值dlmalloc首先brk()方式,如果brk()失败了dlmalloc再尝试mmap()方式。
这篇文章我们来讲讲释放内存的过程,也就是free()的代码流程。对于应用程序来说释放内存很简单,直接调用free(ptr)就可以了,参数是要释放的内存块指针。那么,释放内存时dlmalloc做了哪些工作呢?
[cpp]
- // 这是释放内存的函数,调用free()后执行到这里.
- // 参数mem: 这是将要释放内存的指针
- void dlfree(void* mem) {
- /*
- Consolidate freed chunks with preceeding or succeeding bordering
- free chunks, if they exist, and then place in a bin. Intermixed
- with special cases for top, dv, mmapped chunks, and usage errors.
- */
- // 如果是空指针,那么就不需要处理了.
- if (mem != 0) {
- mchunkptr p = mem2chunk(mem); // 首先找到内存块的起始地址 p = mem - 8.
- #if FOOTERS // 将这个宏看作是0就可以了
- mstate fm = get_mstate_for(p);
- if (!ok_magic(fm)) {
- USAGE_ERROR_ACTION(fm, p);
- return;
- }
- #else /* FOOTERS */
- #define fm gm // 全局变量_gm_的地址
- #endif /* FOOTERS */
- if (!PREACTION(fm)) { // 先加锁
- check_inuse_chunk(fm, p); // 检查这个chunk是否在使用中,这是一个检查函数.
- if (RTCHECK(ok_address(fm, p) && ok_cinuse(p))) {
- size_t psize = chunksize(p); // 计算这个内存块的大小.
- mchunkptr next = chunk_plus_offset(p, psize); // 从这里开始是下一个内存块了.
- if (!pinuse(p)) { // 如果前面一个内存块是空闲的,那么这个内存块释放后就可以跟前面一个内存块合并了.
- size_t prevsize = p->prev_foot; // 前面一个内存块的大小
- if ((prevsize & IS_MMAPPED_BIT) != 0) { // 如果是通过mmap方式创建的内存块
- prevsize &= ~IS_MMAPPED_BIT;
- psize += prevsize + MMAP_FOOT_PAD;
- if (CALL_MUNMAP((char*)p - prevsize, psize) == 0)
- fm->footprint -= psize;
- goto postaction;
- }
- else { // 不是通过mmap方式创建的.
- mchunkptr prev = chunk_minus_offset(p, prevsize); // 取出前面一个chunk的结构.
- psize += prevsize; // 这是两个内存块的总长度
- p = prev; // 这是内存块的起始地址
- if (RTCHECK(ok_address(fm, prev))) { /* consolidate backward */
- if (p != fm->dv) { // 如果不是dv
- unlink_chunk(fm, p, prevsize); // 将这个内存块从malloc_state结构中删除.
- }
- // 如果是dv
- else if ((next->head & INUSE_BITS) == INUSE_BITS) { // 后面一个内存块在使用中,那么就处理完毕了.
- fm->dvsize = psize; // 修改这个chunk的长度.
- set_free_with_pinuse(p, psize, next);
- goto postaction; // 处理完毕
- }
- // 如果后面一个内存块也是空间的,那么还需要将后面一个内存块合并到dv中.
- }
- else
- goto erroraction;
- } // end if ((prevsize & IS_MMAPPED_BIT) != 0)
- } // end if (!pinuse(p))
- // 需要继续检查后面一个内存块是否空闲.
- if (RTCHECK(ok_next(p, next) && ok_pinuse(next))) {
- if (!cinuse(next)) { /* consolidate forward */ // 后面一个内存块也处于空闲状态,那么就可以合并了.
- if (next == fm->top) { // 如果后面一个chunk是top chunk,那么直接将当前合并到top chunk中就可以了.
- size_t tsize = fm->topsize += psize; // 这是合并后top chunk的大小
- fm->top = p; // 这是合并后top chunk的起始地址
- p->head = tsize | PINUSE_BIT;
- if (p == fm->dv) { // 同时也是dv,那么就撤销dv.
- fm->dv = 0;
- fm->dvsize = 0;
- }
- // 现在检查是否需要收缩堆空间,当top chunk大于2mb时收缩堆空间.
- if (should_trim(fm, tsize))
- sys_trim(fm, 0); // 只有这种情况下执行到了sys_trim.
- goto postaction;
- }
- else if (next == fm->dv) { // 如果后面一个chunk是dv,那么直接将本内存块合并到dv中就可以了.
- size_t dsize = fm->dvsize += psize; // 这是合并后dv的大小
- fm->dv = p; // 设置dv新的起始地址
- set_size_and_pinuse_of_free_chunk(p, dsize); // 设置dv新的长度
- goto postaction;
- }
- else { // 后面一个chunk是一个普通的chunk.
- size_t nsize = chunksize(next);
- psize += nsize;
- unlink_chunk(fm, next, nsize); // 先将后面的chunk从malloc_state中摘除.
- set_size_and_pinuse_of_free_chunk(p, psize);
- if (p == fm->dv) {
- fm->dvsize = psize;
- goto postaction;
- }
- }
- } // end if (!cinuse(next))
- else // 后面一个chunk在使用中
- set_free_with_pinuse(p, psize, next); // 修改一些标志信息
- insert_chunk(fm, p, psize); // 将合并后内存块的大小将内存块添加到small bins或者tree bins中.
- check_free_chunk(fm, p);
- goto postaction;
- } // end if (RTCHECK(ok_next(p, next) && ok_pinuse(next)))
- }
- erroraction:
- USAGE_ERROR_ACTION(fm, p);
- postaction:
- POSTACTION(fm);
- }
- }
- #if !FOOTERS
- #undef fm
- #endif /* FOOTERS */
- }
又是很长一大段代码。这段代码首先将内存块标记为空闲,然后根据内存申请方式分别处理。如果内存块大于256kb,那么马上通过munmap()释放内存。如果内存块小于256kb,那么检查相邻的两个内存块是否空闲,如果空闲就跟相邻的内存块合并。然后还需要检查top chunk是否大于2mb。如果top chunk大于2mb,将top chunk释放回内核。
内存块大于256kb时释放内存的代码如下:
[cpp]
- size_t prevsize = p->prev_foot; // 前面一个内存块的大小
- if ((prevsize & IS_MMAPPED_BIT) != 0) { // 如果是通过mmap方式创建的内存块
- prevsize &= ~IS_MMAPPED_BIT;
- psize += prevsize + MMAP_FOOT_PAD;
- if (CALL_MUNMAP((char*)p - prevsize, psize) == 0)
- fm->footprint -= psize;
- goto postaction;
- }
p->prev_foot包含了两项信息:前一个内存块的长度和前一个内存块的创建方式(mmap还是brk)。当申请的内存块大于256kb时dlmalloc通过mmap()申请内存,并为这个内存块创建了一个malloc_chunk结构。由于只有一个malloc_chunk结构,没有相邻的malloc_chunk结构,因此malloc_chunk中的prev_foot字段就没有意义了。这时dlmalloc将prev_foot中比特0用作标志位IS_MMAPPED_BIT,表示这个内存块是通过mmap()方式创建的。因此,如果prev_foot中的IS_MMAPPED_BIT置位了,那么就调用munmap()释放内存(CALL_MUNMAP)。
最后来看看dlmalloc收缩top chunk的代码,这是在函数sys_trim()中实现的,代码如下:[cpp]
- static int sys_trim(mstate m, size_t pad) {
- size_t released = 0;
- if (pad < MAX_REQUEST && is_initialized(m)) {
- pad += TOP_FOOT_SIZE; /* ensure enough room for segment overhead */
- // 调整pad,pad表示需要保留的内存量.
- if (m->topsize > pad) {
- /* Shrink top space in granularity-size units, keeping at least one */
- size_t unit = mparams.granularity; // 申请/释放内存需要是这个值的倍数.
- // 这是需要释放的内存量.
- size_t extra = ((m->topsize - pad + (unit - SIZE_T_ONE)) / unit -
- SIZE_T_ONE) * unit;
- // 取出包含top chunk的segment.
- msegmentptr sp = segment_holding(m, (char*)m->top);
- if (!is_extern_segment(sp)) {
- // 这个segment是通过mmap方式创建的,那么就通过munmap()或者mremap()方式释放内存.
- if (is_mmapped_segment(sp)) {
- if (HAVE_MMAP &&
- sp->size >= extra && // extra是将要释放的内存量
- !has_segment_link(m, sp)) { /* can't shrink if pinned */
- size_t newsize = sp->size - extra; // 计算释放后剩余的内存量
- if ((CALL_MREMAP(sp->base, sp->size, newsize, 0) != MFAIL) ||
- (CALL_MUNMAP(sp->base + newsize, extra) == 0)) {
- released = extra;
- }
- }
- }
- // 这个segment是通过brk方式创建的,那么就通过brk()调整堆的结束位置.
- else if (HAVE_MORECORE) {
- if (extra >= HALF_MAX_SIZE_T) /* Avoid wrapping negative */
- extra = (HALF_MAX_SIZE_T) + SIZE_T_ONE - unit;
- ACQUIRE_MORECORE_LOCK();
- {
- /* Make sure end of memory is where we last set it. */
- char* old_br = (char*)(CALL_MORECORE(0)); // 获取当前堆的结束地址.
- if (old_br == sp->base + sp->size) {
- // 开始收缩堆
- char* rel_br = (char*)(CALL_MORECORE(-extra)); // sbrk()
- char* new_br = (char*)(CALL_MORECORE(0));
- if (rel_br != CMFAIL && new_br < old_br)
- released = old_br - new_br;
- }
- }
- RELEASE_MORECORE_LOCK();
- }
- }
- if (released != 0) {
- sp->size -= released;
- m->footprint -= released;
- init_top(m, m->top, m->topsize - released); // 重新初始化top chunk.
- check_top_chunk(m, m->top);
- }
- } // end if (m->topsize > pad)
- /* Unmap any unused mmapped segments */
- if (HAVE_MMAP)
- released += release_unused_segments(m);
- /* On failure, disable autotrim to avoid repeated failed future calls */
- if (released == 0)
- m->trim_check = MAX_SIZE_T;
- }
- return (released != 0)? 1 : 0;
- }
当申请的内存量小于256kb时,dlmalloc首先通过brk()方式扩展堆,如果失败了会尝试通过mmap()方式申请内存。因此,top chunk可能是通过brk()方式申请的,也可能是通过mmap()方式申请的。如果通过brk()方式申请的,那么就需要通过brk()收缩堆;如果通过mmap()方式申请的,那么就需要通过munmap()或mremap()释放内存